")















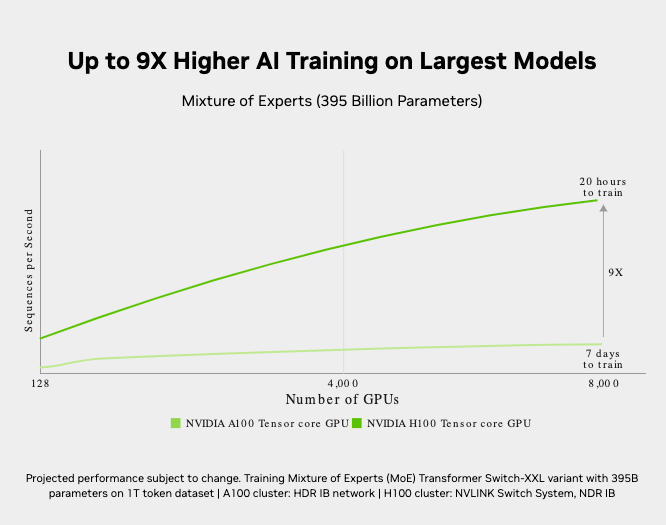
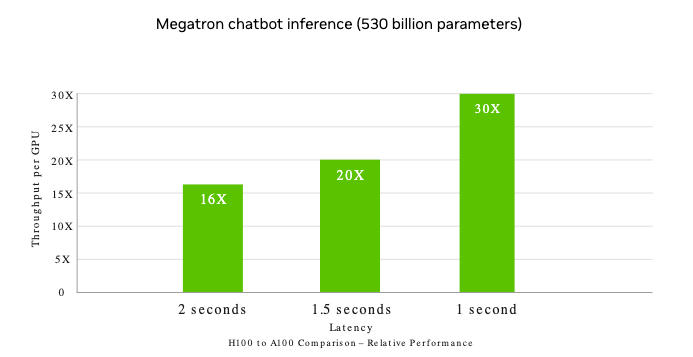
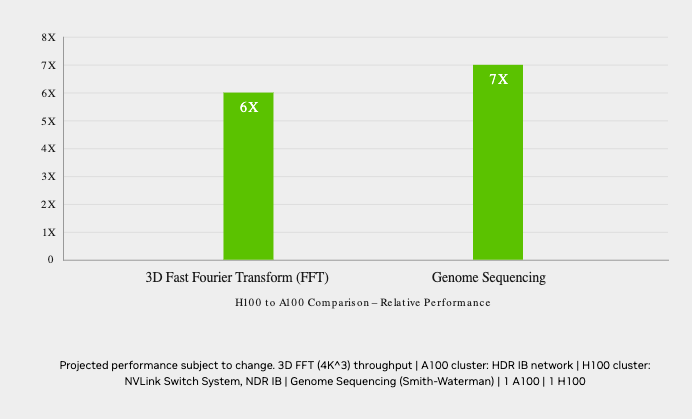

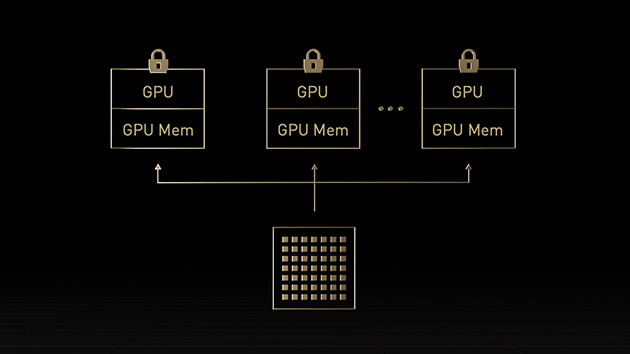

For LLMs up To 175 billion parameters, The PCIe-based H100 NVL With NVLink bridge utilizes Transformer Engine, NVLink, And 188GB HBM3 memory To provide optimum performance And easy scaling across any data center, bringing LLMs To mainstream. Servers equipped With H100 NVL GPUs increase GPT-175B model performance up To 12X over Nvidia DGX™ A100 systems while maintaining low latency in power-constrained data center environments.
Product Specifications
| Form Factor | H100 SXM | H100 PCIe | H100 NVL1 |
|---|---|---|---|
| FP64 | 34 teraFLOPS | 26 teraFLOPS | 68 teraFLOPs |
| FP64 Tensor Core | 67 teraFLOPS | 51 teraFLOPS | 134 teraFLOPs |
| FP32 | 67 teraFLOPS | 51 teraFLOPS | 134 teraFLOPs |
| TF32 Tensor Core | 989 teraFLOPS2 | 756 teraFLOPS2 | 1,979 teraFLOPs2 |
| BFLOAT16 Tensor Core | 1,979 teraFLOPS2 | 1,513 teraFLOPS2 | 3,958 teraFLOPs2 |
| FP16 Tensor Core | 1,979 teraFLOPS2 | 1,513 teraFLOPS2 | 3,958 teraFLOPs2 |
| FP8 Tensor Core | 3,958 teraFLOPS2 | 3,026 teraFLOPS2 | 7,916 teraFLOPs2 |
| INT8 Tensor Core | 3,958 TOPS2 | 3,026 TOPS2 | 7,916 TOPS2 |
| GPU memory | 80GB | 80GB | 188GB |
| GPU memory bandwidth | 3.35TB/s | 2TB/s | 7.8TB/s3 |
| Decoders | 7 NVDEC 7 JPEG | 7 NVDEC 7 JPEG | 14 NVDEC 14 JPEG |
| Max thermal design power (TDP) | Up To 700W (configurable) | 300-350W (configurable) | 2x 350-400W (configurable) |
| Multi-Instance GPUs | Up To 7 MIGS @ 10GB each | Up To 14 MIGS @ 12GB each | |
| Form factor | SXM | PCIe dual-slot air-cooled | 2x PCIe dual-slot air-cooled |
| Interconnect | NVLink: 900GB/s PCIe Gen5: 128GB/s | NVLink: 600GB/s PCIe Gen5: 128GB/s | NVLink: 600GB/s PCIe Gen5: 128GB/s |
| Server options | Nvidia HGX H100 Partner And Nvidia -Certified Systems™ With 4 or 8 GPUs Nvidia DGX H100 With 8 GPUs | Partner And Nvidia -Certified Systems with 1–8 GPUs | Partner And Nvidia -Certified Systems with 2-4 pairs |
| Nvidia AI Enterprise | Add-on | Included | Included |






